The binary Hierarchical Gaussian Filter#
![]()
Show code cell content
import sys
from IPython.utils import io
if 'google.colab' in sys.modules:
with io.capture_output() as captured:
! pip install pyhgf watermark
Show code cell content
import arviz as az
import jax.numpy as jnp
import matplotlib.pyplot as plt
import pymc as pm
from pyhgf import load_data
from pyhgf.distribution import HGFDistribution
from pyhgf.model import HGF
from pyhgf.response import first_level_binary_surprise
plt.rcParams["figure.constrained_layout.use"] = True
WARNING (pytensor.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
In this notebook, we demonstrate how to create and fit the standard two-level and three-level Hierarchical Gaussian Filters (HGF) for binary inputs. This class share a lot of similarities with its continuous counterpart described in the next tutorial. Here, the difference is that the input node accepts binary data. Binary responses are widely used in decision-making neuroscience, and standard reinforcement learning algorithms like Rescorla-Wagner are tailored to learn outcomes probability under such configuration. Here, by using a Hierarchical Gaussian Filter, we want to be able to learn from the evolution of higher-level volatility, and the parameters that are influencing the strength of the coupling between lower-level nodes with their parents (i.e. \(\omega\), or the evolution rate of the 1rst and 2nd levels nodes). The binary version of the Hierarchical Gaussian Filter can take the following structures:

Fig. 3 The two-level and three-level Hierarchical Gaussian Filter for binary inputs. Note that the first level \(X_{0}\) is a binary state node, and has itself a continuous value parent \(X_{1}\). The logit transformation allows to convert the expected probability of the binary state into a continuous value for the parent A volatility parent is only used in the context of a 3-level HGF. This is a specificity of the binary model.#
In this example, we will use data from a decision-making task where the outcome probability was manipulated across time, and observe how the binary HGFs can track switches in response probabilities.
Imports#
We import a time series of binary observations from the decision task described in [Iglesias et al., 2021].
u, _ = load_data("binary")
Fitting the binary HGF with fixed parameters#
The two-level binary Hierarchical Gaussian Filter#
Create the model#
The node structure corresponding to the two-level and three-level Hierarchical Gaussian Filters are automatically generated from model_type and n_levels using the node parameters provided in the dictionaries. Here we are not performing any optimization so those parameters are fixed to reasonable values.
Note
The response function used is the binary surprise at each time point (pyhgf.response.first_level_binary_surprise()). In other words, at each time point the model tries to update its hierarchy to minimize the discrepancy between the expected and real next binary observation. See also this tutorial to see how to create a custom response function.
two_levels_hgf = HGF(
n_levels=2,
model_type="binary",
initial_mean={"1": 0.5, "2": 0.0},
initial_precision={"1": 1.0, "2": 1.0},
tonic_volatility={"2": -3.0},
)
This function creates an instance of an HGF model automatically parametrized for a two-level binary structure, so we do not have to worry about creating the node structure ourselves. This class also embed function to add new observations and plot results that we are going to use below. We can have a look at the node structure itself using the pyhgf.plots.plot_network() function. This function will automatically dray the provided node structure using Graphviz.
two_levels_hgf.plot_network()

Add data#
# Provide new observations
two_levels_hgf = two_levels_hgf.input_data(input_data=u)
Plot trajectories#
A Hierarchical Gaussian Filter acts as a Bayesian filter when presented with new observation, and by running the update equation forward, we can observe the trajectories of the parameters of the node that are being updated after each new observation (i.e. the mean \(\mu\) and the precision \(\pi\)). The plot_trajectories function automatically extracts the relevant parameters given the model structure and plots their evolution together with the input data.
two_levels_hgf.plot_trajectories(show_total_surprise=True);
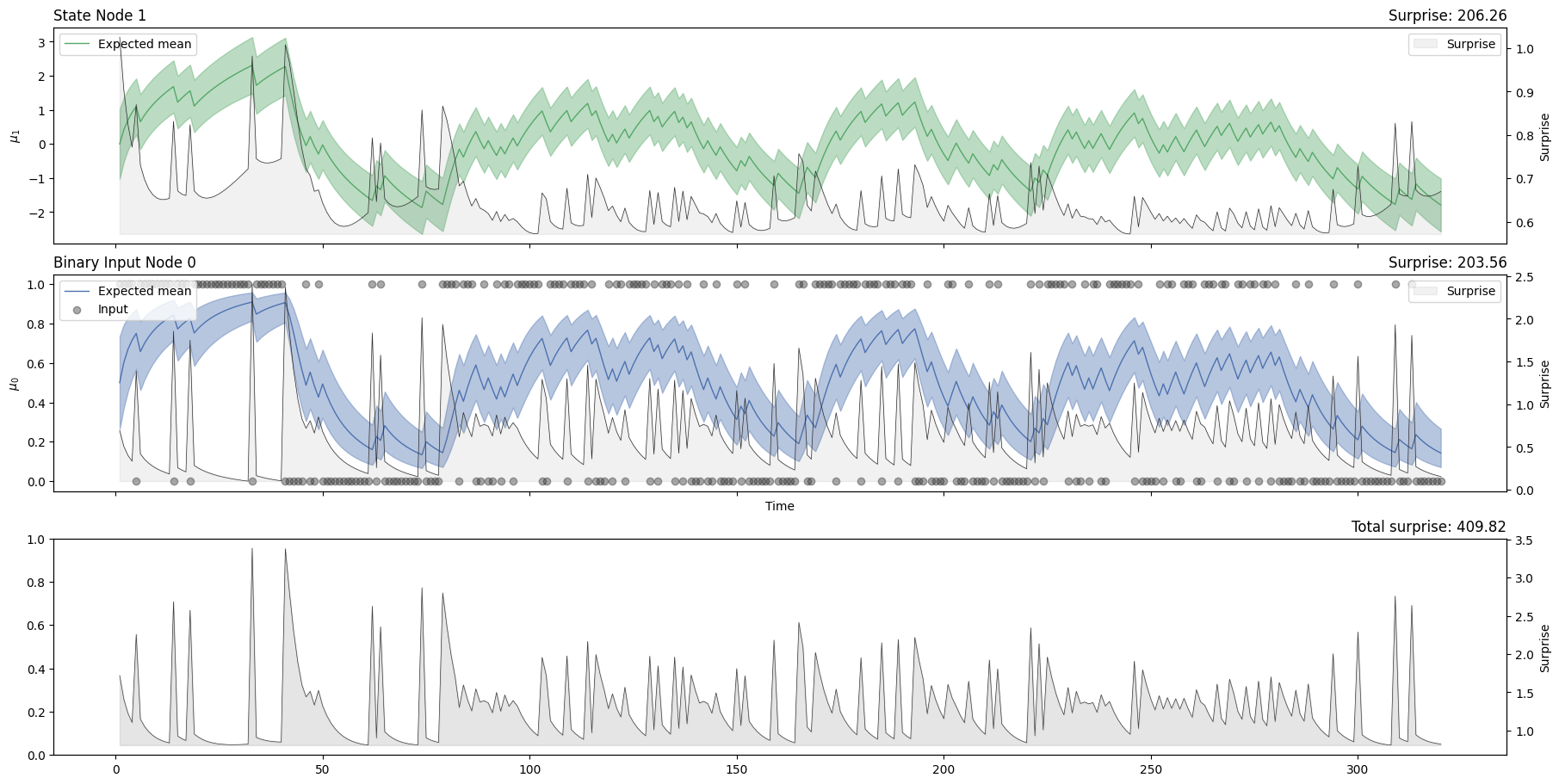
Surprise#
We can see that the surprise will increase when the time series exhibits more unexpected behaviours. The degree to which a given observation is expected will depend on the expected value and volatility in the input node, which is influenced by the values of higher-order nodes. One way to assess model fit is to look at the total binary surprise for each observation. These values can be returned from the fitted model using the surprise method:
two_levels_hgf.surprise().sum()
Array(203.55585, dtype=float32)
Note
The surprise of a model under the observation of new data directly depends on the response function that was used. New response functions can be added and provided using different response_function_parameters and response_function in the pyhgf.model.HGF.surprise() method. The surprise is then defined as the negative log probability of new observations:
The three-level binary Hierarchical Gaussian Filter#
Create the model#
Here, we create a new pyhgf.model.HGF instance, setting the number of levels to 3. Note that we are extending the size of the dictionaries accordingly.
three_levels_hgf = HGF(
n_levels=3,
model_type="binary",
initial_mean={"1": 0.0, "2": 0.5, "3": 0.0},
initial_precision={"1": 0.0, "2": 1.0, "3": 1.0},
tonic_volatility={"1": None, "2": -3.0, "3": -2.0},
tonic_drift={"1": None, "2": 0.0, "3": 0.0},
volatility_coupling={"1": None, "2": 1.0},
eta0=0.0,
eta1=1.0,
binary_precision=jnp.inf,
)
The node structure now includes a volatility parent at the third level.
three_levels_hgf.plot_network()

Add data#
three_levels_hgf = three_levels_hgf.input_data(input_data=u)
Plot trajectories#
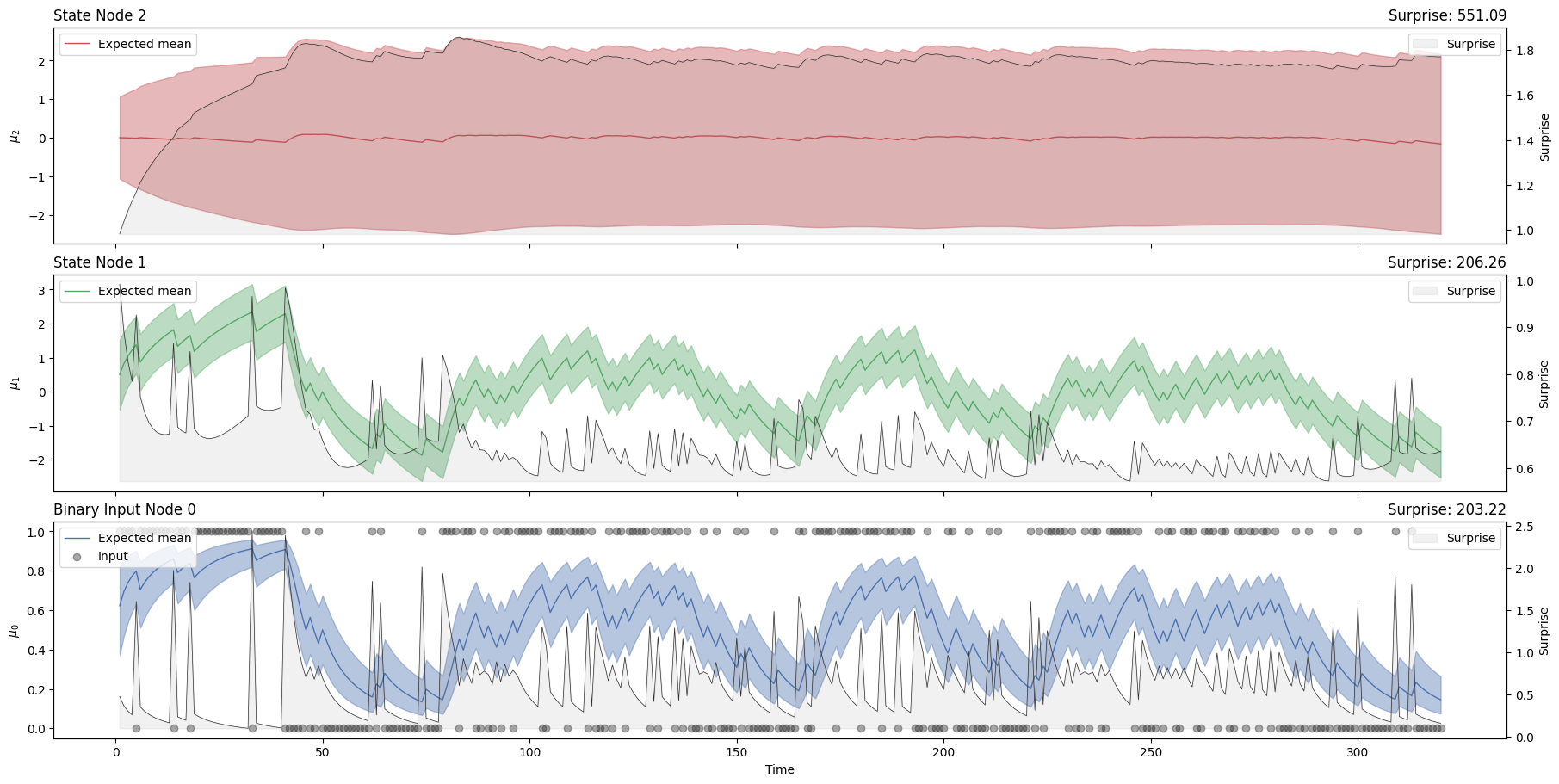
three_levels_hgf.plot_trajectories();
Show code cell content
# ensure that the results are valid
df = three_levels_hgf.to_pandas()
assert jnp.isclose(df.x_0_surprise.sum(), 203.21596)
assert jnp.isclose(df.x_1_surprise.sum(), 206.2633)
assert jnp.isclose(df.x_2_surprise.sum(), 551.09045)
Surprise#
three_levels_hgf.surprise().sum()
Array(203.21596, dtype=float32)
Learning parameters with MCMC sampling#
In the previous section, we assumed we knew the parameters of the HGF models that were used to filter the input data. This can give us information on how an agent using these values would behave when presented with these inputs. We can also adopt a different perspective and consider that we want to learn these parameters from the data. Here, we are going to set some of the parameters free and use Hamiltonian Monte Carlo methods (NUTS) to sample their probability density.
Because the HGF classes are built on the top of JAX, they are natively differentiable and compatible with optimisation libraries or can be embedded as regular distributions in the context of a Bayesian network. Here, we are using this approach, and we are going to use PyMC to perform this step. PyMC can use any log probability function (here the negative surprise of the model) as a building block for a new distribution by wrapping it in its underlying tensor library Aesara, now forked as PyTensor. This PyMC-compatible distribution can be found in the pyhgf.distribution sub-module.
Two-level model#
Creating the model#
hgf_logp_op = HGFDistribution(
n_levels=2,
model_type="binary",
input_data=u[jnp.newaxis, :],
response_function=first_level_binary_surprise,
)
Note
The data is being passed to the distribution when the instance is created, so we won’t use the observed argument in our PyMC model.
with pm.Model() as two_levels_binary_hgf:
# Set a prior over the evolution rate at the second level.
tonic_volatility_2 = pm.Uniform("tonic_volatility_2", -3.5, 0.0)
# Call the pre-parametrized HGF distribution here.
# All parameters are set to their default value, except omega_2.
pm.Potential("hgf_loglike", hgf_logp_op(tonic_volatility_2=tonic_volatility_2))
Visualizing the model#
pm.model_to_graphviz(two_levels_binary_hgf)

Sampling#
with two_levels_binary_hgf:
two_level_hgf_idata = pm.sample(chains=2, cores=1)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Sequential sampling (2 chains in 1 job)
NUTS: [tonic_volatility_2]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 6 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
az.plot_trace(two_level_hgf_idata, var_names=["tonic_volatility_2"]);

Using the learned parameters#
To visualize how the model would behave under the most probable values, we average the \(\omega_{2}\) samples and use this value in a new model.
tonic_volatility_2 = az.summary(two_level_hgf_idata)["mean"]["tonic_volatility_2"]
hgf_mcmc = HGF(
n_levels=2,
model_type="binary",
initial_mean={"1": jnp.inf, "2": 0.5},
initial_precision={"1": 0.0, "2": 1.0},
tonic_volatility={"1": jnp.inf, "2": tonic_volatility_2},
tonic_drift={"1": 0.0, "2": 0.0},
volatility_coupling={"1": 1.0},
).input_data(input_data=u)
hgf_mcmc.plot_trajectories(show_total_surprise=True);
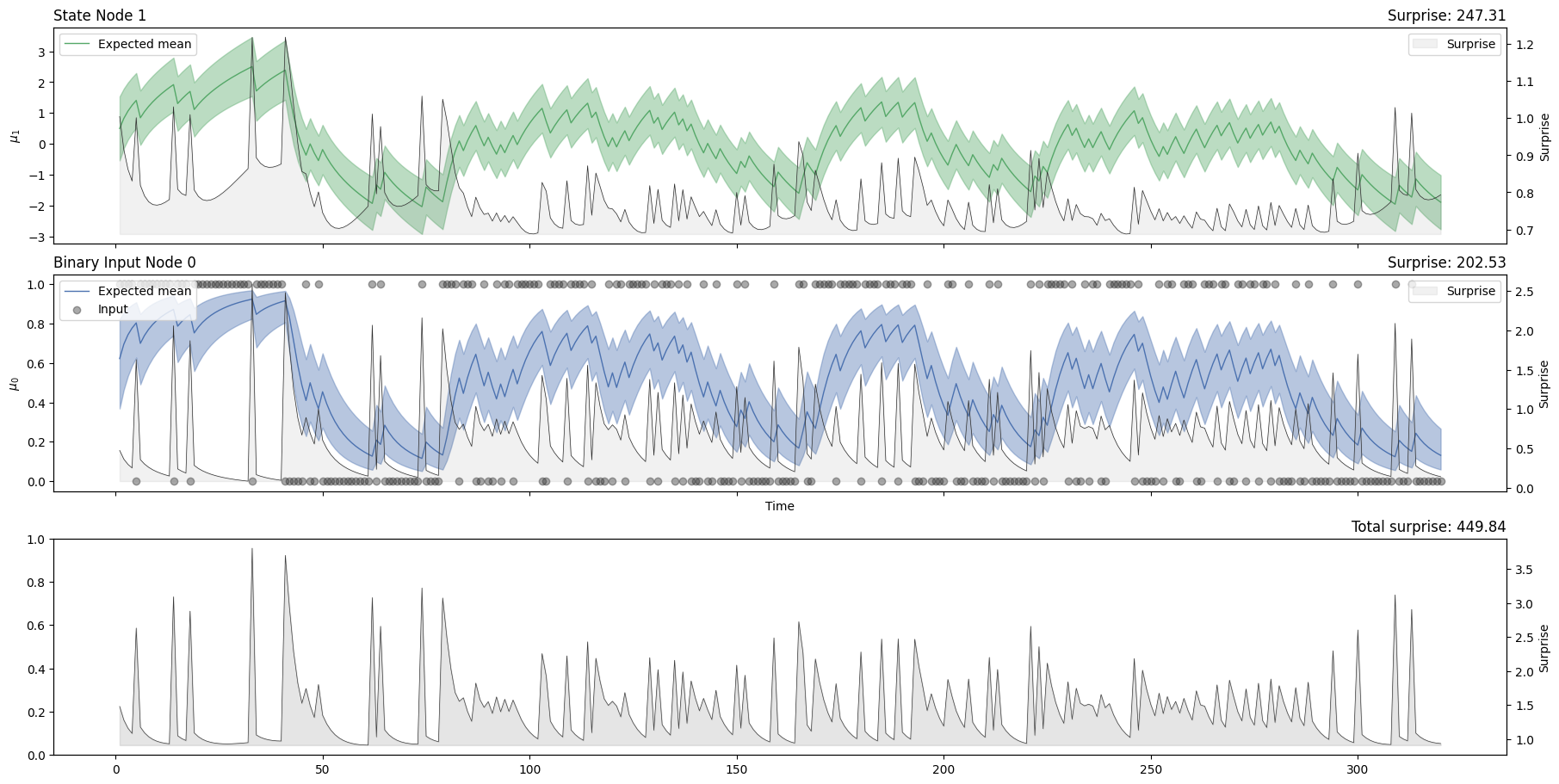
hgf_mcmc.surprise().sum()
Array(202.52966, dtype=float32)
Three-level model#
Creating the model#
hgf_logp_op = HGFDistribution(
n_levels=3,
model_type="binary",
input_data=u[jnp.newaxis, :],
response_function=first_level_binary_surprise,
)
with pm.Model() as three_levels_binary_hgf:
# Set a prior over the evolution rate at the second and third levels.
tonic_volatility_2 = pm.Uniform("tonic_volatility_2", -4.0, 0.0)
tonic_volatility_3 = pm.Normal("tonic_volatility_3", -11.0, 2)
# Call the pre-parametrized HGF distribution here.
# All parameters are set to their default value except omega_2 and omega_3.
pm.Potential(
"hgf_loglike",
hgf_logp_op(
tonic_volatility_2=tonic_volatility_2, tonic_volatility_3=tonic_volatility_3
),
)
Visualizing the model#
pm.model_to_graphviz(three_levels_binary_hgf)

Sampling#
with three_levels_binary_hgf:
three_level_hgf_idata = pm.sample(chains=2, cores=1)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Sequential sampling (2 chains in 1 job)
NUTS: [tonic_volatility_2, tonic_volatility_3]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 10 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
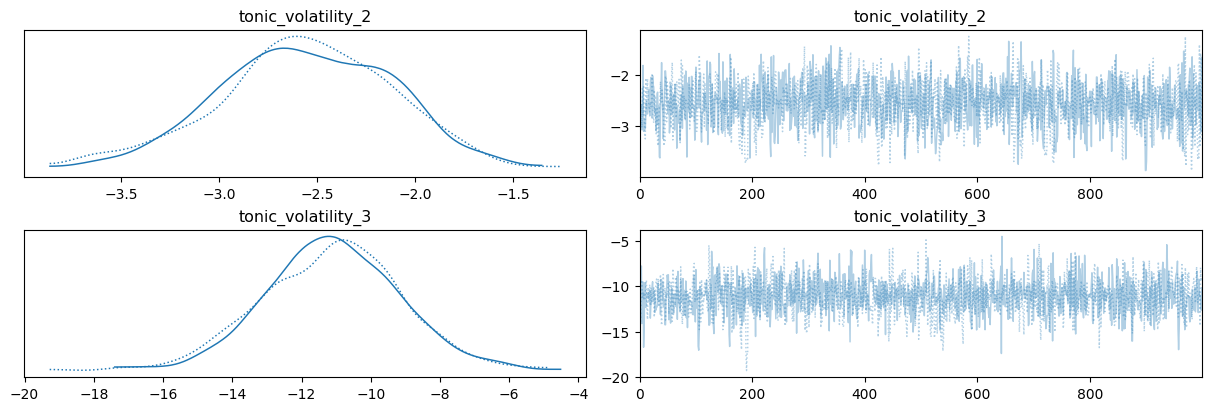
az.plot_trace(
three_level_hgf_idata, var_names=["tonic_volatility_2", "tonic_volatility_3"]
);
Using the learned parameters#
To visualize how the model would behave under the most probable values, we average the \(\omega_{2}\) samples and use this value in a new model.
tonic_volatility_2 = az.summary(three_level_hgf_idata)["mean"]["tonic_volatility_2"]
tonic_volatility_3 = az.summary(three_level_hgf_idata)["mean"]["tonic_volatility_3"]
hgf_mcmc = HGF(
n_levels=3,
model_type="binary",
initial_mean={"1": jnp.inf, "2": 0.5, "3": 0.0},
initial_precision={"1": 0.0, "2": 1e4, "3": 1e1},
tonic_volatility={"1": jnp.inf, "2": tonic_volatility_2, "3": tonic_volatility_3},
tonic_drift={"1": 0.0, "2": 0.0, "3": 0.0},
volatility_coupling={"1": 1.0, "2": 1.0},
).input_data(input_data=u)
hgf_mcmc.plot_trajectories();
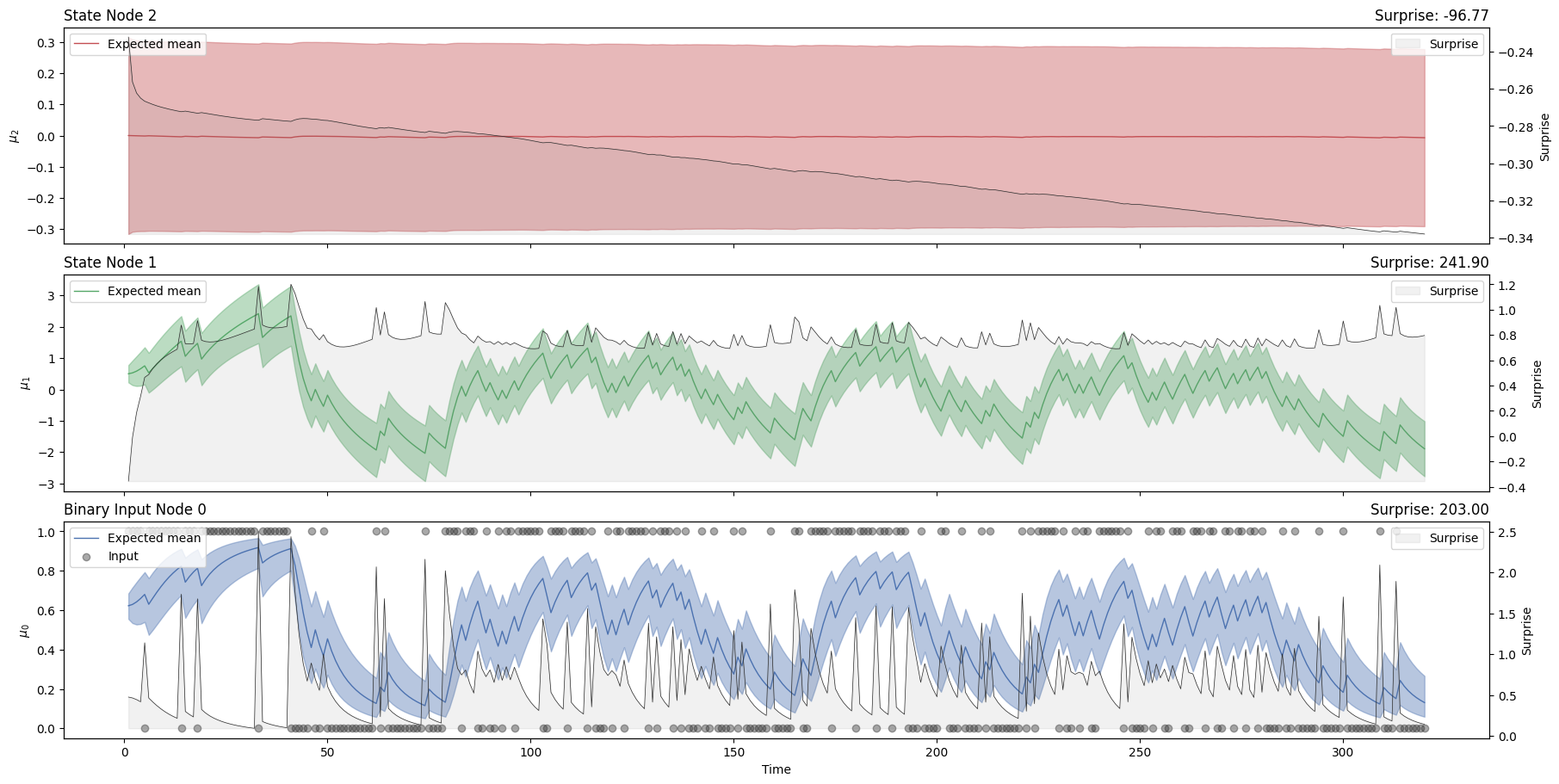
hgf_mcmc.surprise().sum()
Array(203.0036, dtype=float32)
System configuration#
%load_ext watermark
%watermark -n -u -v -iv -w -p pyhgf,jax,jaxlib
Last updated: Sun Oct 13 2024
Python implementation: CPython
Python version : 3.12.7
IPython version : 8.28.0
pyhgf : 0.2.0
jax : 0.4.31
jaxlib: 0.4.31
arviz : 0.20.0
pyhgf : 0.2.0
sys : 3.12.7 (main, Oct 1 2024, 15:17:55) [GCC 11.4.0]
IPython : 8.28.0
jax : 0.4.31
matplotlib: 3.9.2
pymc : 5.17.0
Watermark: 2.5.0